|
随着AI和大数据蓬勃发展,Python语言成为增长最快的语言。在TIOBE最新发布的2022年03月份编程语言指数排行榜中,Python再次成功登顶,已经不再是性能无所谓的脚本语言。
从腾讯大数据产品使用经验来看,Python正深刻影响着海量应用的功能和性能。Python的动态类型为用户提供便利的同时也成为程序bug的来源和性能优化的障碍。在实际生产环境中,我们观察到Python程序总体负载占比达12~18%,性能和资源占用不确定,成为数据中心资源可用性、系统稳定性的风险点。
Microsoft、Facebook、Pyston在2021年5月陆续推出自己的Cpython性能提升计划和开源项目,来提升Python虚拟机的性能。Microsoft的Faster CPython项目计划4年实现5倍性能提升,平均每年1.5倍;通过自适应和特例化解释器来提升执行性能,后续会引入JIT。Facebook的Cinder针对不同用例能够实现1.5-4倍的性能提升,实现了MethodJIT、缓存机制以及基于类型注释的性能优化。Pyston对一组测试用例有1.3倍性能提升,实现了TracingJIT和激进的缓存机制。
腾讯大数据编译器团队,紧贴大数据和机器学习等业务场景,在Python领域持续投入,致力于提升Python性能。我们基于Cpython,发布并验证了性能增强的Python虚拟机TPython。
▍需求分析
我们发现围绕Python的最突出需求来自于以下三个方面: 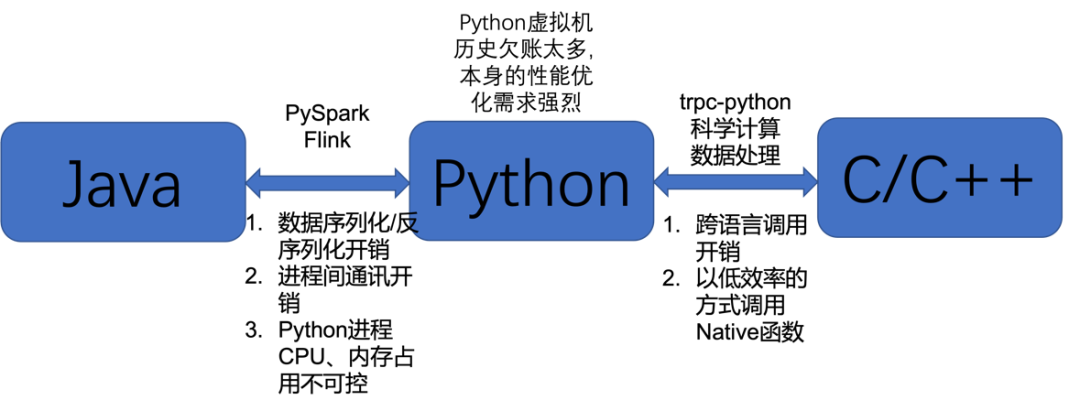
1. Java和Python交互时,Java和Python之间过程间通讯和对象转换开销较大,部分情况下系统吞吐率下降10倍;Python进程占用CPU和内存不可控,当前通常是Python进程需要多少CPU和内存就分配多少,这样会影响同时运行的其他程序的资源分配。
2. C/C++和Python交互时,跨语言调用开销较大;由于对Native实现的不了解甚至误解,导致以效率低的方式调用Native函数。
3. Python虚拟机历史欠账太多,本身的性能优化需求强烈。
▍优化方案
针对上面不同层次的需求,TPython提出了系统化的优化方案:
减少运行态字节码数量合并指令,降低运行时跳转和分支预测失败率
优化函数调用和对象访问流程lnline cache without JIT基于寄存器的解释器,删除冗余的push/pop
实现Tracing/Method JIT, 支持Hidden Class、Hidden Inheritance、vtable显式表示RC和NULL-checking等操作,删除冗余操作构建Alias, SSA, 实现DSE, Prop等常规优化删除冗余语句对于Primitive type,实现基于escape analysis的box/unbox删除
Python进程数量可配置调整GC触发条件,降低GC频率,控制内存占用降低reference counting开销
减少跨语言跨进程的序列化/反序列化开销发现接口误用跨语言的IPA
▍当前进展
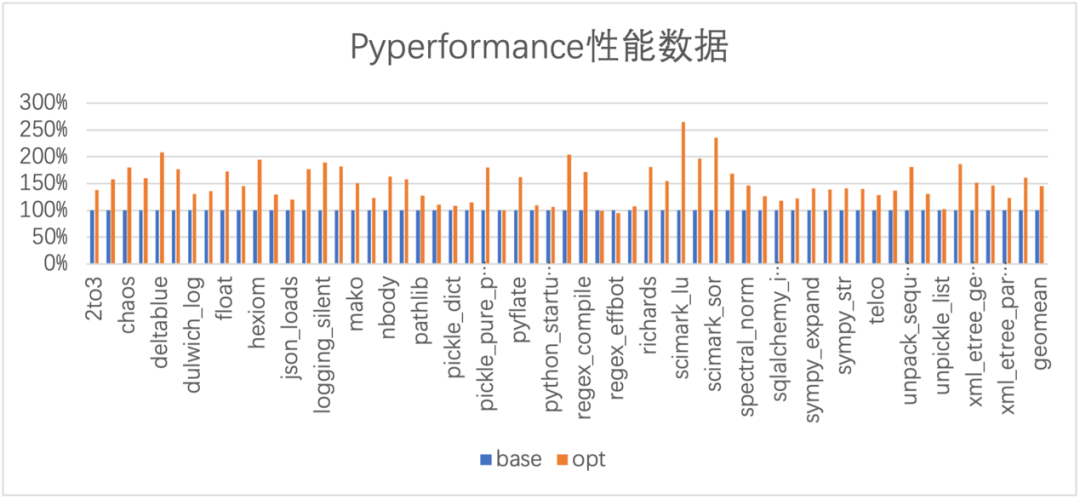
当前TPython主要关注解释器和运行时相关优化,基于寄存器的解释器和JIT处于设计阶段。下面简单介绍一下已经实现的部分优化:循环中Global变量的外提,部分函数内联,指令的特化(PEP 659),局部性优化,GC调参等。对Pyperformance 58个测试用例平均有46%的性能提升。
1、LICM
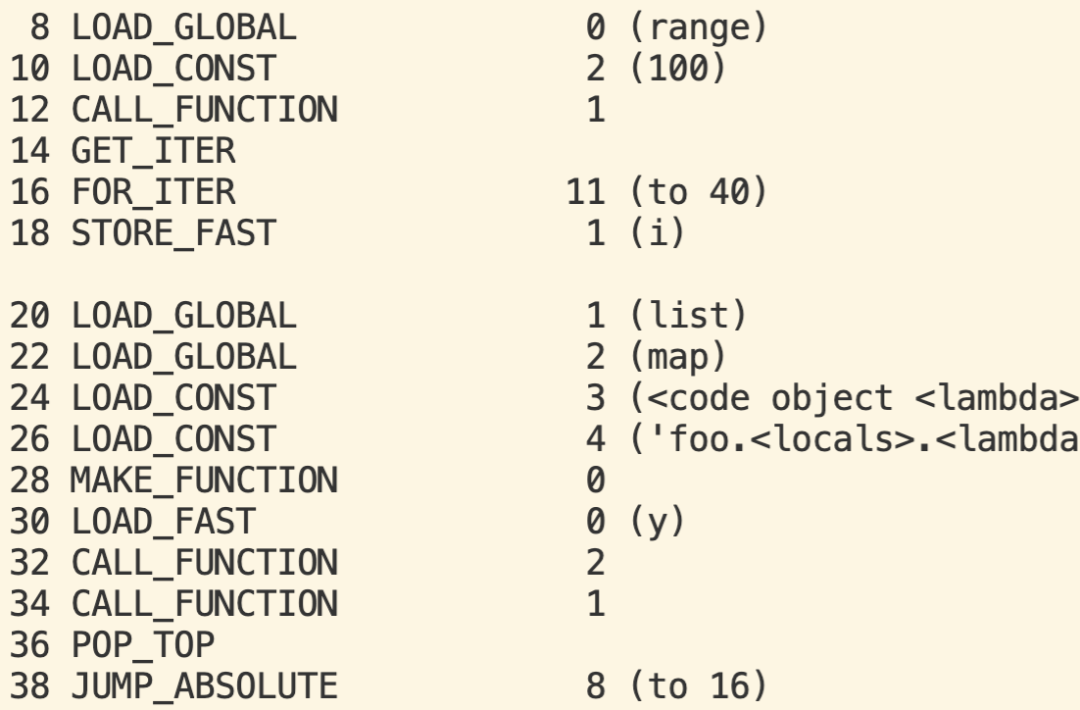
针对如下用例:def foo(): y = [1, 2, 3, 4, 5, 6, 7, 8, 9] for i in range(100): list(map(lambda x: x * abs(x), y))
代码片段1
优化前生成的字节码如下:
优化后生成的字节码如下:
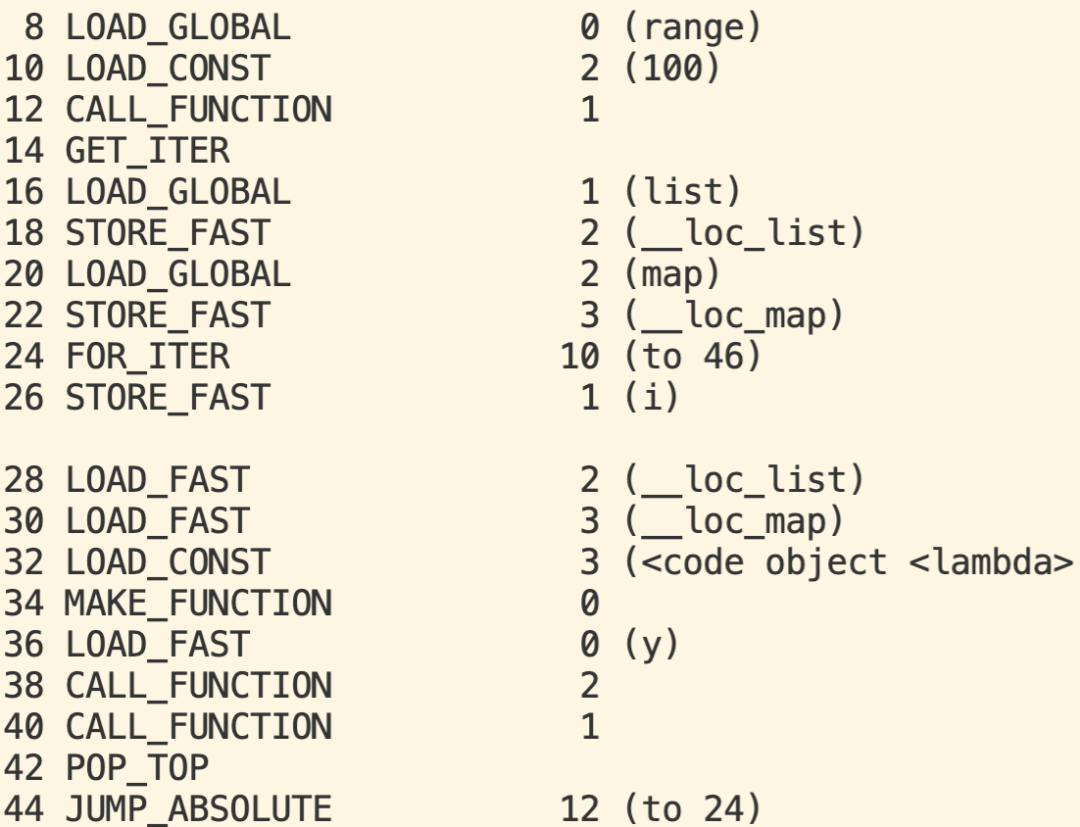
可以看到在循环中重度操作LOAD_GLOBAL被替换成轻量级操作LOAD_FAST。实测性能变化如下:有12%的性能提升。
python -m timeit -s 'y = [1, 2, 3, 4, 5, 6, 7, 8, 9]' 'for i in range(100):' ' list(map(lambda x: x * abs(x), y))'2000 loops, best of 5: 108 usec per looppython-base -m timeit -s 'y = [1, 2, 3, 4, 5, 6, 7, 8, 9]' 'for i in range(100):' ' list(map(lambda x: x * abs(x), y))'2000 loops, best of 5: 123 usec per loop
2、函数内联
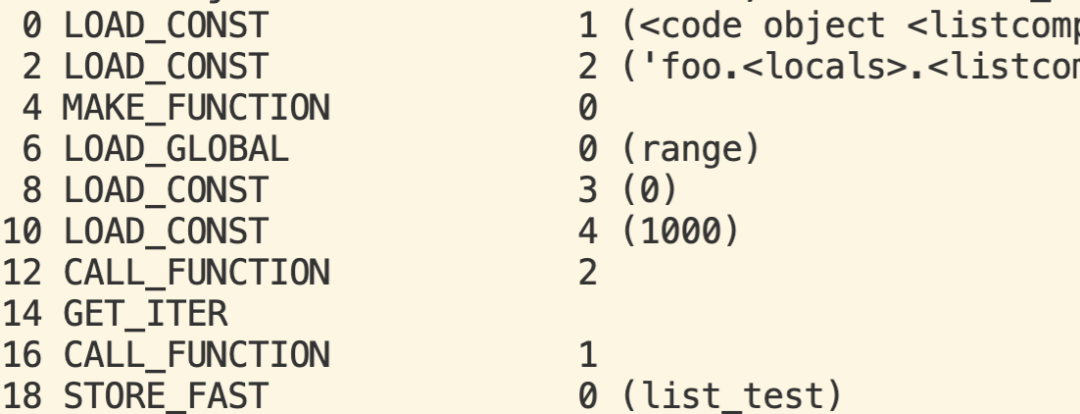
针对如下用例:def foo(): list_test = [i for i in range(0, 1000)] list_filter = [i for i in range(0, 1000) if i > len("abc")]
代码片段2
第二行代码优化前生成的字节码如下:
优化后生成的字节码如下:
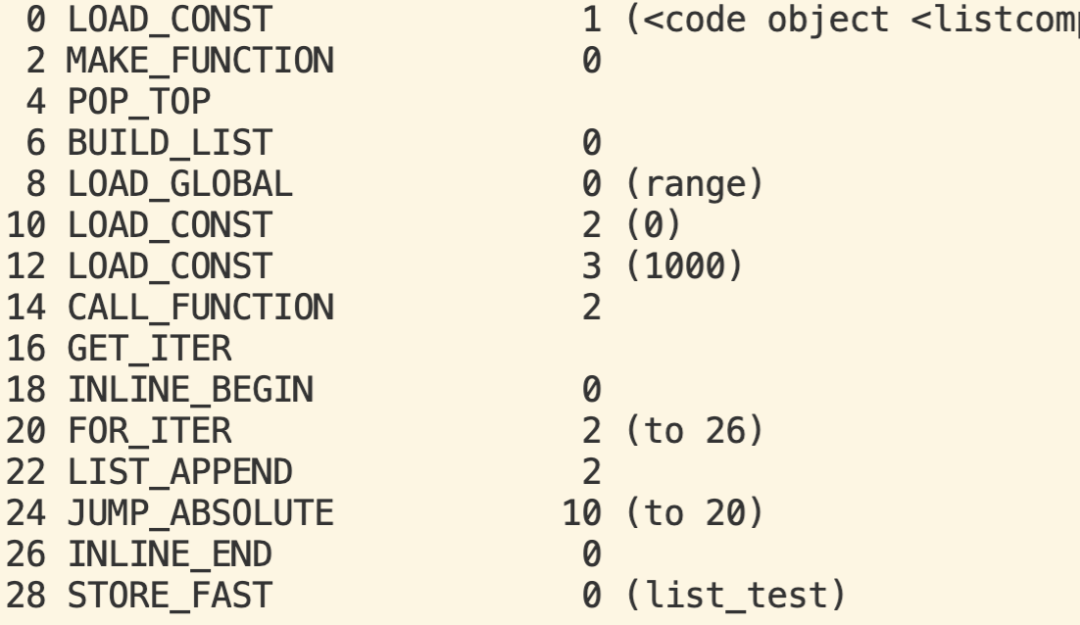
可以看到优化后原来第16行的CALL_FUNCTION被Callee的函数体代替了。实测性能变化如下:有11%的性能提升。
python -m timeit -s 'list_test = [i for i in range(0, 1000)]' 'list_filter = [i for i in range(0, 1000) if i > len("abc")]'5000 loops, best of 5: 56.4 usec per looppython-base -m timeit -s 'list_test = [i for i in range(0, 1000)]' 'list_filter = [i for i in range(0, 1000) if i > len("abc")]'5000 loops, best of 5: 63.3 usec per loop
3、Peephole和指令特化
下图是代码片段2中第2行中List Comprehension对应的字节码:

优化后的字节码如下:

我们可以看出原来的第6行和第8行的字节码被删掉了。
下图是代码片段2中第3行中List Comprehension对应的字节码:
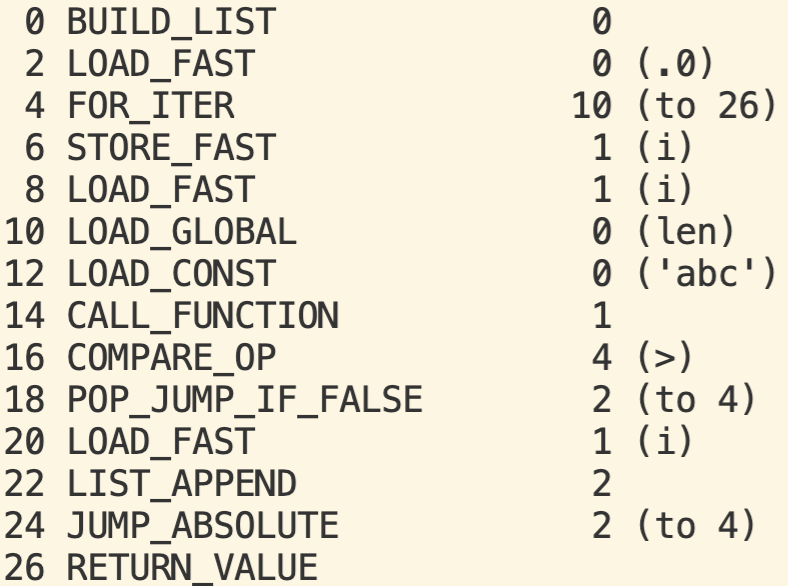
优化后的字节码如下:
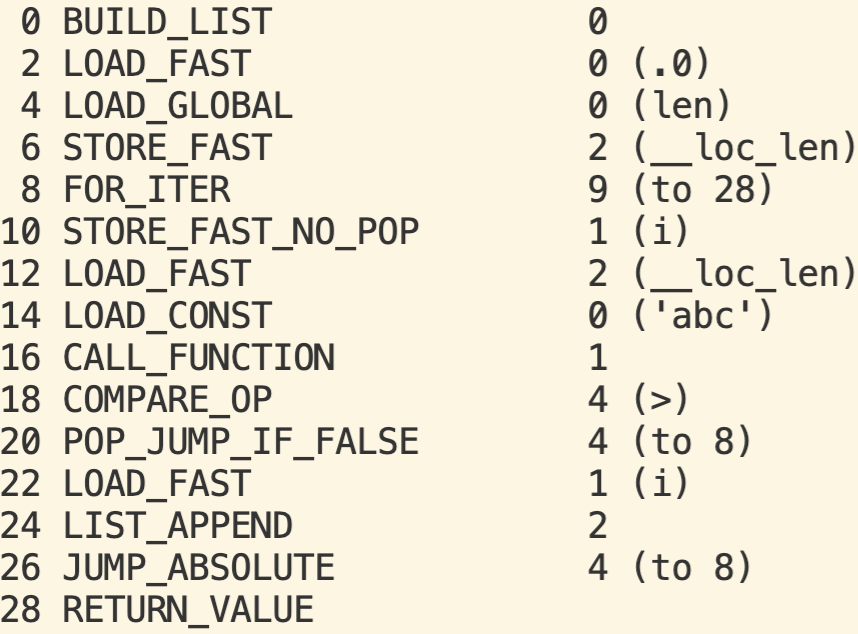
我们可以看出原来第6行和第8行的字节码被替换成一条新字节码STORE_FAST_NO_POP。STORE_FAST_NO_POP删除了原来Push/Pop开销和第二条LOAD_FAST的开销。
4、超级指令UNPACK_SEQUENCE_ST
针对如下用例:def foo(pairs): for (([x1, y1, z1], v1, m1), ([x2, y2, z2], v2, m2)) in pairs: dx = x1 - x2 dy = y1 - y2 dz = z1 - z2
代码片段3
第二行代码优化前生成的字节码如下:

优化后生成的字节码如下:

可以看到优化后原来第10行的UNPACK_SEQUENCE被新指令UNPACK_SEQUENCE_ST代替了。UNPACK_SEQUENCE_ST实现了UNPACK功能并根据Args的值对后续N条指令进行赋值,减少了Push/Pop的开销和后续指令查找的开销。实测对Pyperformance中的unpack_sequence有20+%的性能提升。
5、POP_JUMP_IF_(NOT_)NONE
对于类似(if xxx is None 的语句,生成的字节码如下: 的语句,生成的字节码如下:

我们引入了新的字节码POP_JUMP_IF_(NOT_)NONE,减少了字节码数量和相关操作。

6、跳转表局部性优化
Cpython解释器采用threaded code模式实现派遣,使用一个显式跳转表且在每个字节码指令最后有一个显式的间接跳转操作。Cpython跳转表有256项,在64位机器上大小为2KB。当前跳转表的布局比较随意,我们发现跳转表项的访问频率差别很大。下面是Pyperformance测试集的字节码指令访问频率的profile信息。通过调整表项布局增强局部性,可以提高解释器性能。
('LOAD_FAST', 622332466) ('LOAD_FAST__LOAD_FAST', 266954602) ('LOAD_CONST', 238168478) ('POP_JUMP_IF_FALSE', 233629262) ('LOAD_ATTR_SPLIT_KEYS', 176211584) ('LOAD_FAST__LOAD_CONST', 127900968)
7、GC调参
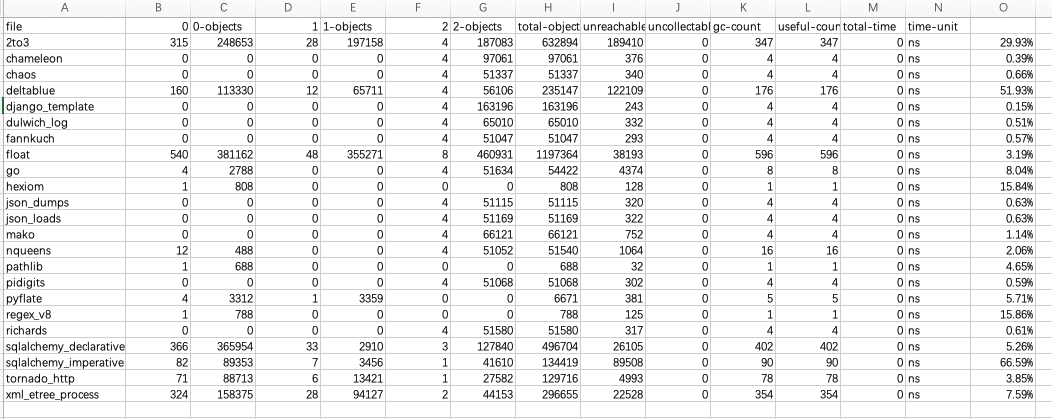
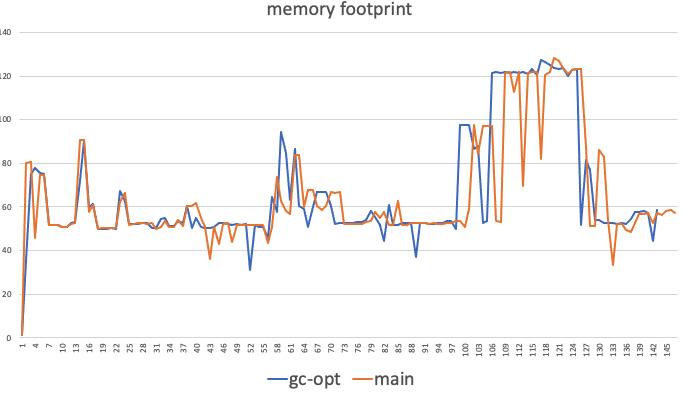
上图是Pyperformance部分用例的GC统计信息,最左边一列显示绝大多数GC操作在扫描对象,但是真正回收的对象比例非常小。我们通过调整GC的阈值降低了GC频率,内存占用峰值基本没变化,程序性能得到了提升。
8、性能评估
我们使用48核2GHz AMD EPYC 7K62服务器进行测试。GCC版本是gcc8.3.1,编译选项和系统默认安装的Python3.6.8一致。测试集选择Pyperformance,包括58个测试用例。相对于Python3.6.8,整体性能提升46%。
 ▍总结 ▍总结
人生苦短,我用Python。是时候认真考虑Python性能了,避免浪费人生!
|
 |Archiver|手机版|小黑屋|鲁公网安备 37082802000167号|微信邦
( 鲁ICP备19043418号-5 )
|Archiver|手机版|小黑屋|鲁公网安备 37082802000167号|微信邦
( 鲁ICP备19043418号-5 )


 发表于 2022-5-20 09:18:04
发表于 2022-5-20 09:18:04
